
Correlation, regression, and prediction
If you run into errors, check the common errors Google doc first.
One of the most important and interesting aspects of data science is making predictions about the future. How can we learn about temperatures a few decades from now by analyzing historical data about climate change and pollution? Based on a person’s social media profile, what conclusions can we draw about their interests? How can we use a patient’s medical history to judge how well he or she will respond to a treatment?
Run the cell below to import the code we’ll use in this notebook. Don’t worry about getting an output, simply run the cell.
from datascience import *
import numpy as np
import matplotlib.pyplot as plots
import scipy as sp
%matplotlib inline
import statsmodels.formula.api as smf
plots.style.use('fivethirtyeight')
In this module, you will look at two correlated phenomena and predict unseen data points!
We will be using data from the online data archive of Prof. Larry Winner of the University of Florida. The file hybrid contains data on hybrid passenger cars sold in the United States from 1997 to 2013. In order to analyze the data, we must first import it to our Jupyter notebook and create a table.
hybrid = Table.read_table('data/hybrid.csv') # Imports the data and creates a table
hybrid.show(5) # Displays the first five rows of the table
| vehicle | year | msrp | acceleration | mpg | class |
|---|---|---|---|---|---|
| Prius (1st Gen) | 1997 | 24509.7 | 7.46 | 41.26 | Compact |
| Tino | 2000 | 35355 | 8.2 | 54.1 | Compact |
| Prius (2nd Gen) | 2000 | 26832.2 | 7.97 | 45.23 | Compact |
| Insight | 2000 | 18936.4 | 9.52 | 53 | Two Seater |
| Civic (1st Gen) | 2001 | 25833.4 | 7.04 | 47.04 | Compact |
... (148 rows omitted)
References: vehicle: model of the car, year: year of manufacture, msrp: manufacturer’s suggested retail price in 2013 dollars, acceleration: acceleration rate in km per hour per second, mpg: fuel economy in miles per gallon, class: the model’s class.
Note: whenever we write an equal sign (=) in python, we are assigning somthing to a variable.
Let’s visualize some of the data to see if we can spot a possible association!
hybrid.scatter('acceleration', 'msrp') # Creates a scatter plot of two variables in a table
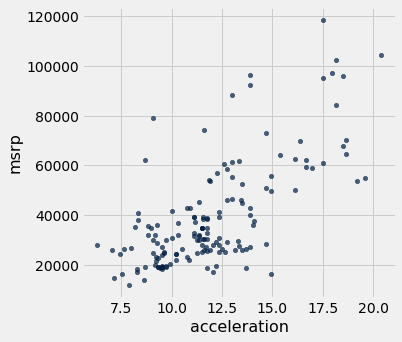
As we can see in the above scatter, there seems to be a positive association between acceleration and price. That is, cars with greater acceleration tend to cost more, on average; conversely, cars that cost more tend to have greater acceleration on average.
What about miles per gallon and price? Do you expect a positive or negative association?
hybrid.scatter('mpg', 'msrp')
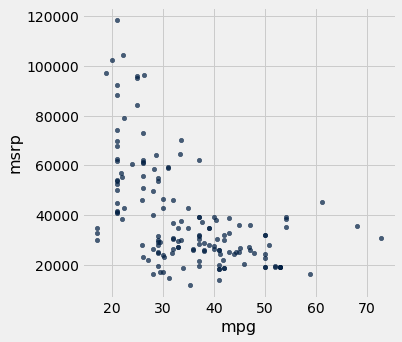
Along with the negative association, the scatter diagram of price versus efficiency shows a non-linear relation between the two variables, i.e., the points appear to be clustered around a curve, not around a straight line.
Let’s subset the data so that we’re only looking at SUVs. Use what you learned in the previous notebook to choose only SUVs and then make a scatter plot of mpg and msrp:
# task
The correlation coefficient - r
The correlation coefficient ranges from −1 to 1. A value of 1 implies that a linear equation describes the relationship between X and Y perfectly, with all data points lying on a line for which Y increases as X increases. A value of −1 implies that all data points lie on a line for which Y decreases as X increases. A value of 0 implies that there is no linear correlation between the variables. ~Wikipedia
r = 1: the scatter diagram is a perfect straight line sloping upwards
r = -1: the scatter diagram is a perfect straight line sloping downwards.
Let’s calculate the correlation coefficient between acceleration and price. We can use the np.corrcoef function on the two variable (columns here) that we want to correlate:
sp.stats.pearsonr(hybrid['acceleration'], hybrid['msrp'])
(0.6955778996913979, 1.9158000667128373e-23)
This function two numbers. The first number is our r value, and the second number is the p-value for our correlation. A p-value of under .05 indicates strong validity in the correlation. Our coefficient here is 0.6955779, and our p-value is low implying strong positive correlation.
Regression
As mentioned earlier, an important tool in data science is to make predictions based on data. The code that we’ve created so far has helped us establish a relationship between our two variables. Once a relationship has been established, it’s time to create a model that predicts unseen data values. To do this we’ll find the equation of the regression line!
The regression line is the best fit line for our data. It’s like an average of where all the points line up. In linear regression, the regression line is a perfectly straight line! Below is a picture showing the best fit line.
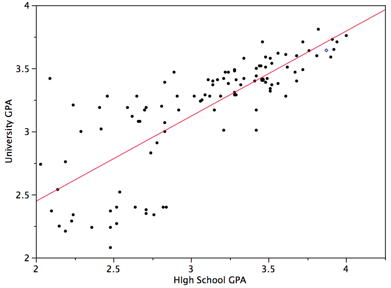
As you can infer from the picture, once we find the slope and the y-intercept we can start predicting values! The equation for the above regression to predict university GPA based on high school GPA would look like this:
$UNIGPA_i= \alpha + \beta HSGPA + \epsilon_i$
The variable we want to predict (or model) is the left side y variable, the variable which we think has an influence on our left side variable is on the right side. The $\alpha$ term is the y-intercept and the $\epsilon_i$ describes the randomness.
We can fit the model by setting up an equation without the $\alpha$ and $\epsilon_i$ in the formula parameter of the function below, we’ll give it our data variable in the data parameter. Then we just fit the model and ask for a summary. We’ll try a model for:
$MSRP_i= \alpha + \beta ACCELERATION + \epsilon_i$
mod = smf.ols(formula='msrp ~ acceleration', data=hybrid.to_df())
res = mod.fit()
print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: msrp R-squared: 0.484
Model: OLS Adj. R-squared: 0.480
Method: Least Squares F-statistic: 141.5
Date: Wed, 22 May 2019 Prob (F-statistic): 1.92e-23
Time: 22:33:36 Log-Likelihood: -1691.7
No. Observations: 153 AIC: 3387.
Df Residuals: 151 BIC: 3394.
Df Model: 1
Covariance Type: nonrobust
================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------
Intercept -2.128e+04 5244.588 -4.058 0.000 -3.16e+04 -1.09e+04
acceleration 5067.6611 425.961 11.897 0.000 4226.047 5909.275
==============================================================================
Omnibus: 32.737 Durbin-Watson: 1.656
Prob(Omnibus): 0.000 Jarque-Bera (JB): 52.692
Skew: 1.072 Prob(JB): 3.61e-12
Kurtosis: 4.915 Cond. No. 52.1
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
That’s a lot of information! While we should consider everything, we’ll look at the p value, the coef, and the R-squared. A p-value of < .05 is generally considered to be statistically significant. The coef is how much increase one sees in the left side variable for a one unit increase of the right side variable. So for a 1 unit increase in acceleration one might see an increase of $5067 MSRP, according to our model. But how great is our model? That’s the R-squared. The R-squared tells us how much of the variation in the data can be explained by our model, .484 isn’t that bad, but obviously more goes into the MSRP value of a car than just acceleration.
We can plot this line of “best fit” too:
hybrid.scatter('acceleration', 'msrp', fit_line=True)
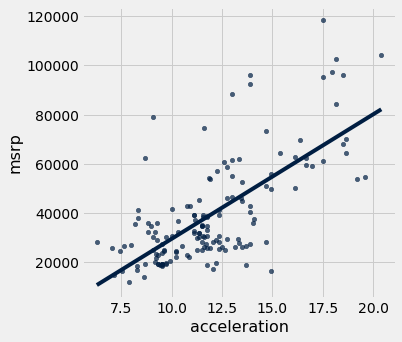
Covariate
We might want to add another independent variable because we think it could influence our dependent variable. If we think mpg could have an influence and needs to be controlled for we just + add that to the equation. (NB: the example below would exhibit high multicollinearity)
$MSRP_i= \alpha + \beta ACCELERATION + \beta MPG + \epsilon_i$
mod = smf.ols(formula='msrp ~ acceleration + mpg', data=hybrid.to_df())
res = mod.fit()
print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: msrp R-squared: 0.527
Model: OLS Adj. R-squared: 0.521
Method: Least Squares F-statistic: 83.66
Date: Wed, 22 May 2019 Prob (F-statistic): 3.93e-25
Time: 22:33:37 Log-Likelihood: -1685.0
No. Observations: 153 AIC: 3376.
Df Residuals: 150 BIC: 3385.
Df Model: 2
Covariance Type: nonrobust
================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------
Intercept 5796.5295 8861.211 0.654 0.514 -1.17e+04 2.33e+04
acceleration 4176.4342 474.195 8.807 0.000 3239.471 5113.398
mpg -471.9015 127.066 -3.714 0.000 -722.973 -220.830
==============================================================================
Omnibus: 24.929 Durbin-Watson: 1.614
Prob(Omnibus): 0.000 Jarque-Bera (JB): 33.903
Skew: 0.922 Prob(JB): 4.35e-08
Kurtosis: 4.384 Cond. No. 282.
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
We are going to walk through a brief example using the datasets that you will using. You will not be allowed to use this correlation for your project. However, the process for your project will be the same. Our goal is to make the project as seamless as possible for you. That being said, our example will be abbreviated so that you have some freedom to explore with your own data.
First we are going to read in two datasets.
Implicit-Age-IAT.csv gives us the implicit age bias according to FIPS code.
age = Table.read_table('Implicit-Age_IAT.csv')
age.show(5)
| FIPS | tyoung | told | D_biep_Young_Good_all |
|---|---|---|---|
| 10001 | 7.13782 | 7.17363 | 0.462662 |
| 10003 | 7.07723 | 6.88274 | 0.439701 |
| 10005 | 6.84831 | 6.96089 | 0.445957 |
| 1001 | 7.05085 | 6.79661 | 0.502814 |
| 1003 | 7.17904 | 7.04148 | 0.457369 |
... (3133 rows omitted)
Outcome-Heart-Attack-Mortality.csv gives us the heart attack mortality count by year according to FIPS code.
heart = Table.read_table('Outcome-Heart-Attack-Mortality.csv')
heart.show(5)
| State | FIPS | County | Year | Heart_Attack_Mortality | Stability |
|---|---|---|---|---|---|
| Alabama | 1001 | Autauga | 2000 | 220.8 | 1 |
| Alabama | 1001 | Autauga | 2001 | 100.7 | 1 |
| Alabama | 1001 | Autauga | 2002 | 68.2 | 1 |
| Alabama | 1001 | Autauga | 2003 | 66.7 | 1 |
| Alabama | 1001 | Autauga | 2005 | 63.2 | 1 |
... (34780 rows omitted)
Keep in mind that all the functions/syntax that we are using are either in this notebook, or the previous one from lecture.
Now, we are going to join the two tables together. We will be joining on the ‘FIPS’ column because that’s the only one they have in common! That column is a unique identifier for counties. We are also going to drop duplicate rows from the table.
joined_data = age.join("FIPS", heart)
joined_data = joined_data.to_df().drop_duplicates()
joined_data = Table.from_df(joined_data)
joined_data
| FIPS | tyoung | told | D_biep_Young_Good_all | State | County | Year | Heart_Attack_Mortality | Stability |
|---|---|---|---|---|---|---|---|---|
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2000 | 220.8 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2001 | 100.7 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2002 | 68.2 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2003 | 66.7 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2005 | 63.2 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2006 | 68.3 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2007 | 73.9 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2008 | 104.7 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2009 | 60 | 1 |
| 1001 | 7.05085 | 6.79661 | 0.502814 | Alabama | Autauga | 2010 | 93.2 | 1 |
... (34706 rows omitted)
That’s great! By displaying the table, we can get a general idea as to what columns exist, and what kind of relations we can try to analyze.
One thing to notice is that there are a lot of data points! Our visualization and regression may be cleaner if we subset the data. Let’s use the functions from the first notebook to subset the data to California data from 2010.
joined_data = joined_data.where("Year", are.equal_to(2010))
joined_data = joined_data.where("State", are.equal_to("California"))
joined_data
| FIPS | tyoung | told | D_biep_Young_Good_all | State | County | Year | Heart_Attack_Mortality | Stability |
|---|---|---|---|---|---|---|---|---|
| 6001 | 6.96069 | 6.78826 | 0.423026 | California | Alameda | 2010 | 45.8 | 1 |
| 6005 | 6.575 | 6.85 | 0.446357 | California | Amador | 2010 | 78.6 | 1 |
| 6007 | 7.11892 | 7.04696 | 0.442157 | California | Butte | 2010 | 62.7 | 1 |
| 6009 | 7.65079 | 7.8254 | 0.460807 | California | Calaveras | 2010 | 99.5 | 1 |
| 6013 | 6.96188 | 6.87655 | 0.418506 | California | Contra Costa | 2010 | 48.9 | 1 |
| 6015 | 7 | 6.83871 | 0.43266 | California | Del Norte | 2010 | 75.8 | 1 |
| 6017 | 6.84016 | 6.85714 | 0.408486 | California | El Dorado | 2010 | 53.9 | 1 |
| 6019 | 7.0461 | 7.09315 | 0.424963 | California | Fresno | 2010 | 80.4 | 1 |
| 6021 | 6.6 | 7.2 | 0.260103 | California | Glenn | 2010 | 91.7 | 1 |
| 6023 | 6.86624 | 6.79618 | 0.433324 | California | Humboldt | 2010 | 94.4 | 1 |
... (39 rows omitted)
We now have a lot less points, which will hopefully make the visualization a bit cleaner.
Let’s make a simple scatter plot with a fit line to look at the relation between the category D_biep_Young_Good_all and Heart_Attack_Mortality. Remember, all these functions are either on Notebook 1 or Notebook 2!
joined_data.scatter("D_biep_Young_Good_all", "Heart_Attack_Mortality", fit_line = True)
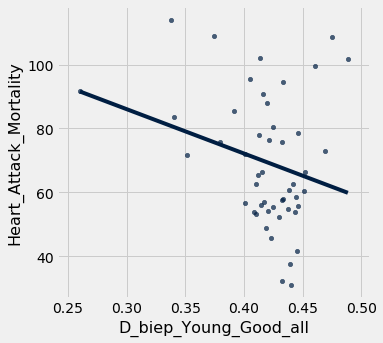
As we can see, the correlation and subsequent linear fit do not seem to be good. That means that there is not an easily quantifiable relationship between implicit age bias and the heart attack mortality rate for that geographic region.
Let’s verify this quantitatively with an r-value calculation!
sp.stats.pearsonr(joined_data['D_biep_Young_Good_all'], joined_data['Heart_Attack_Mortality'])
(-0.2566592892097549, 0.0750451858488917)
Our r-value is moderately negative, and our p-value is pretty low, but not < .05, so we would not reject the null hypothesis and call this “significant”. This indicates little to no correlation, similar to what our scatter plot predicited.
Let us display a regression summary, just for practice!
mod = smf.ols(formula='Heart_Attack_Mortality ~ D_biep_Young_Good_all + told', data=joined_data.to_df())
res = mod.fit()
print(res.summary())
OLS Regression Results
==================================================================================
Dep. Variable: Heart_Attack_Mortality R-squared: 0.067
Model: OLS Adj. R-squared: 0.027
Method: Least Squares F-statistic: 1.661
Date: Wed, 22 May 2019 Prob (F-statistic): 0.201
Time: 22:33:40 Log-Likelihood: -215.40
No. Observations: 49 AIC: 436.8
Df Residuals: 46 BIC: 442.5
Df Model: 2
Covariance Type: nonrobust
=========================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------------
Intercept 104.0577 93.565 1.112 0.272 -84.278 292.394
D_biep_Young_Good_all -133.0227 79.819 -1.667 0.102 -293.690 27.645
told 3.0434 11.323 0.269 0.789 -19.749 25.836
==============================================================================
Omnibus: 3.154 Durbin-Watson: 1.878
Prob(Omnibus): 0.207 Jarque-Bera (JB): 2.932
Skew: 0.585 Prob(JB): 0.231
Kurtosis: 2.744 Cond. No. 269.
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
A quick scan above shows an extremeley low R-squared and a high p-value, both of which imply that our model does not fit the data very well at all.
That’s it! By working through this module, you’ve learned how to visually analyze your data, establish a correlation by calculating the correlation coefficient, set up a regression (with a covariate), and find the regression line!
If you need help, please consult the Data Peers!