Estimated Time: 25-30 Minutes
Professor: Elizabeth Schwartz
Developers: Rinrada Maneenop
Textbook Reference: OpenStax Introductory Statistics 2e, Chapter 12 (Linear Regression and Correlation)
Goal: Learn the basics of scatter plots, correlation, and simple linear regression with guided practice.
Table of Contents¶
Quick Concepts and Setup
Load and View the Data
Scatter Plot (Always Start Here)
Correlation Coefficient
rRegression Line
Prediction and Caution About Extrapolation
Short Practice Exercises
Notebook Structure¶
You will see short example -> practice cycles.
This instructor notebook includes completed code everywhere the student version used .... For distribution, use linear_regression.ipynb and keep this file private.
Run cells top to bottom to verify output on your machine.
This notebook follows OpenStax Ch. 12 guidance:
start with a scatter plot,
use
rto describe strength/direction,use the regression line for prediction only when linear and within the observed x-range.
1. Introduction¶
1.1. Learning Objectives¶
Do NBA players who score more points earn higher salaries? Are there other stats that might predict pay even better? In this notebook, we’ll use real NBA player data to explore these questions using the tools of linear regression and correlation. By the end, you will:
Understand what a scatter plot tells us about the relationship between two variables
Measure the strength of a linear relationship using the correlation coefficient r
Calculate and interpret a regression line (line of best fit)
Use the regression line to make predictions
Apply these skills to explore a relationship of your own choosing in the sandbox
1.2. What is Linear Regression?¶
Suppose you want to predict an NBA player’s salary based on how many points they score per game. You have data on hundreds of players, but there’s no perfect rule — a player who scores 20 points a game doesn’t always earn exactly twice as much as one who scores 10. Instead, the data follows a trend.
Linear Regression is a method that finds the straight line that best describes this trend. The line has the form:
ŷ = a + b · x
Where:
x is the independent variable (the input — e.g., points per game)
ŷ (“y-hat”) is the predicted value of the dependent variable (the output — e.g., salary)
b is the slope — how much ŷ changes for each 1-unit increase in x
a is the y-intercept — the value of ŷ when x equals 0
Before fitting a line, we also measure correlation — a number between -1 and 1 that describes how strongly and in which direction two variables move together.
1.3. Setup¶
Below, we have imported the Python libraries needed for this module. Run the code in this cell before running any other code cells, and be careful not to change any of the code.
You can run the cell in any of these ways:
Ctrl + Enter: Run the cell and keep the cursor in the same cell.
Shift + Enter: Run the cell and move the cursor to the next cell.
Click the Play button: Click the Run (play) button to the left of the cell to execute it.
import numpy as np
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
from visuals import (
show_interactive_correlation,
show_interactive_line_tuner,
show_prediction_slider,
show_sandbox_regression,
)
# Make plots look clean
sns.set_theme(style="whitegrid")
plt.rcParams["figure.figsize"] = (8, 5)2. Data Preparation¶
2.1. Loading the Data¶
We will work with an NBA player dataset from the Data 8 Spring 2025 course materials. It contains statistics and salary information for NBA players across a season. Let’s load it and take a first look!
# Load the dataset from the Data 8 SP25 review sandbox
url = "https://raw.githubusercontent.com/data-8/materials-sp25/main/review-sandbox/nba.csv"
nba = pd.read_csv(url)
# Display the first 10 rows
display(nba.head(10))
print(f"Shape: {nba.shape[0]} rows x {nba.shape[1]} columns")
print(f"Columns: {list(nba.columns)}")Shape: 525 rows x 14 columns
Columns: ['Player', 'Salary Rank', 'Salary', 'Player Rank', 'Age', 'Team', 'Position', 'Games', 'Rebounds', 'Assists', 'Steals', 'Blocks', 'Turnovers', 'Points']
2.2. Exploring the Data¶
Before we do any analysis, let’s get a feel for the numbers. The cell below prints summary statistics — the mean, standard deviation, minimum, and maximum — for all numeric columns.
# Summary statistics for numeric columns
display(nba.describe().round(2))Question 2.2. Look at the summary statistics for Salary. What is the average salary? What is the range (min to max)? Does the spread surprise you — and why or why not?
Your Answer Here
2.3. Cleaning the Data¶
Real-world data often has missing values. Let’s check whether any rows are missing Salary or Points, and drop those rows so our analysis is based on complete records only.
import pandas as pd
url = "https://raw.githubusercontent.com/data-8/materials-sp25/main/review-sandbox/nba.csv"
nba = pd.read_csv(url)
print("Missing values per column:")
print(nba.isnull().sum())
print()
nba_clean = nba.dropna(subset=["Salary", "Points"]).copy()
print(f"Rows before cleaning: {len(nba)}")
print(f"Rows after cleaning: {len(nba_clean)}")Missing values per column:
Player 0
Salary Rank 0
Salary 0
Player Rank 0
Age 0
Team 0
Position 0
Games 0
Rebounds 0
Assists 0
Steals 0
Blocks 0
Turnovers 0
Points 0
dtype: int64
Rows before cleaning: 525
Rows after cleaning: 525
Question 2.3. Why is it important to remove rows with missing Salary or Points values before fitting a regression line? What might happen to our analysis if we left them in?
Your Answer Here
3. Visualizing the Data¶
3.1. Scatter Plots¶
A scatter plot is always the first step when studying the relationship between two numerical variables. For correlation and regression we use Age (years) vs Games (games played) — a weak but real linear link whose p-value prints as an ordinary decimal (unlike Points vs Salary, where (r) is so strong that the p-value is essentially 0 in scientific notation). Each dot is one player.
When looking at a scatter plot, ask yourself:
Does the cloud of points slope upward (positive), downward (negative), or show no pattern (no relationship)?
How tightly clustered are the points around an imaginary line?
Are there any outliers that sit far from the rest?
fig, ax = plt.subplots()
ax.scatter(nba_clean["Age"], nba_clean["Games"],
alpha=0.45, color="steelblue", edgecolors="white", s=65)
ax.set_xlabel("Age (years)", fontsize=12)
ax.set_ylabel("Games played", fontsize=12)
ax.set_title("NBA Players: Age vs. Games Played", fontsize=14)
plt.tight_layout()
plt.show()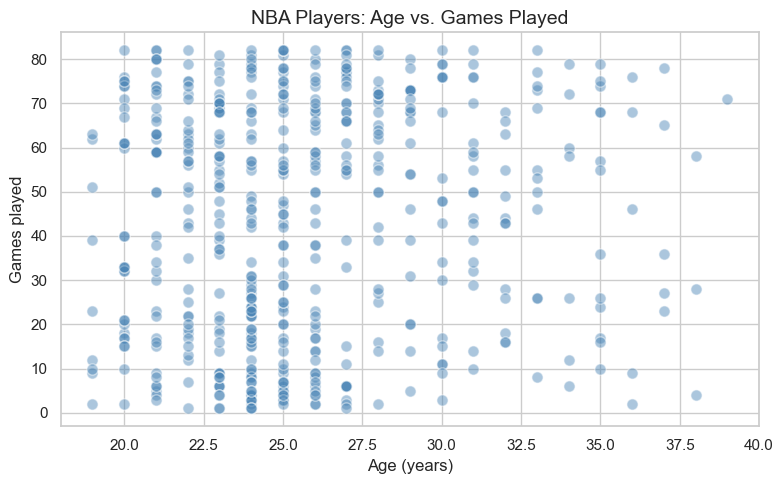
Question 3.1. Describe what you see in the scatter plot. Is there a clear direction to the relationship? Does it look linear? Would you say the relationship is strong or weak — and why?
Your Answer Here
Question 3.2. Do you notice any outliers — players who seem to earn much more than their scoring average would predict? What might explain why a player commands a very high salary without being a top scorer?
Your Answer Here
4. The Correlation Coefficient¶
4.1. What Does r Tell Us?¶
The correlation coefficient, written as r, is a single number between -1 and +1 that captures the strength and direction of the linear relationship between two variables.
| Value of r | Interpretation |
|---|---|
| Close to +1 | Strong positive relationship — as x increases, y tends to increase |
| Close to -1 | Strong negative relationship — as x increases, y tends to decrease |
| Close to 0 | Little to no linear relationship |
| Exactly +1 or -1 | Perfect linear relationship (all points on one line) |
Use the interactive visual below to build intuition:
Move the
Target rslider to change direction/strength.Click Generate New Sample to see that random samples vary, even with the same target correlation.
show_interactive_correlation()4.2. Computing r¶
Now let’s compute r for Age vs Games. We’ll use software to get both r and a p-value. The p-value tells us whether the correlation is statistically significant — i.e., whether it’s unlikely to have occurred by random chance alone. A p-value below 0.05 is typically considered significant. (Here (r) is modest and p is on the order of 0.04 — easy to read — not astronomically small like for Points vs Salary.)
x = nba_clean["Age"]
y = nba_clean["Games"]
r, p_value = stats.pearsonr(x, y)
print(f"Correlation coefficient (r): {r:.4f}")
print(f"p-value: {p_value:.4f}")Correlation coefficient (r): 0.0880
p-value: 0.0440
Question 4.1 (Code Practice — instructor solution). The next code cell shows the completed answer for extracting and interpreting the correlation for Age vs Games.
# Instructor solution: interpret the correlation result
r_value = r # use the value already computed above
if r_value > 0:
direction = "positive"
else:
direction = "negative"
print(f"r = {r_value:.3f}")
print(f"Direction: {direction}")
r = 0.088
Direction: positive
Question 4.2 (Code Practice — instructor solution). The next code cell shows the completed significance test at alpha = 0.05.
# Instructor solution: significance at alpha = 0.05
alpha = 0.05
is_significant = p_value < alpha
print(f"p-value = {p_value:.4f}")
print(f"Significant at alpha={alpha}? {is_significant}")
if is_significant:
print("There is evidence of a linear relationship between Age and games played.")
else:
print("There is not enough evidence of a linear relationship.")
p-value = 0.0440
Significant at alpha=0.05? True
There is evidence of a linear relationship between Age and games played.
5. The Regression Line¶
5.1. Slope and Intercept¶
# Sections 5–6: regression uses Games (x) vs Salary Rank (y)
pair = nba_clean[["Games", "Salary Rank"]].dropna()
x = pair["Games"]
y = pair["Salary Rank"]
r, p_value = stats.pearsonr(x, y)
From here through Section 6, we take Games as the predictor () and Salary Rank as the response (). Salary Rank runs from 1 (highest salary on the team) upward — so lower rank numbers correspond to higher salaries.
We fit a regression line — the single straight line that minimizes the total squared distance between itself and all the data points. This is called the Least Squares Regression Line.
The formulas for slope and intercept are:
: slope of the regression line (how much predicted Salary Rank changes for one additional game played)
: correlation coefficient between and
: standard deviation of (here,
Salary Rank): standard deviation of (here,
Games)
: intercept of the regression line (predicted salary rank when games played = 0 — not meaningful for real players, but part of the math)
: mean of
: mean of
: observed value of the independent variable
: predicted value from the regression line
Let’s compute these step by step using the Chapter 12 formulas.
# Step 1: Compute means and standard deviations
x_mean, y_mean = x.mean(), y.mean()
x_std, y_std = x.std(), y.std()
print(f"Mean Games : {x_mean:.3f}")
print(f"Mean Salary Rank: {y_mean:.3f}")
print(f"Std Games : {x_std:.3f}")
print(f"Std Salary Rank: {y_std:.3f}")Mean Games : 43.370
Mean Salary Rank: 294.055
Std Games : 26.226
Std Salary Rank: 171.743
# Step 2: Compute slope (b) and intercept (a)
b = r * (y_std / x_std)
a = y_mean - b * x_mean
print(f"Slope (b) : {b:.4f} change in salary rank per additional game played")
print(f"Intercept (a) : {a:.4f}")
print(f"\nRegression equation: y_hat = {a:.4f} + {b:.4f} * x")Slope (b) : -4.0190 change in salary rank per additional game played
Intercept (a) : 468.3568
Regression equation: y_hat = 468.3568 + -4.0190 * x
# Textbook check: the least-squares line passes through (x_mean, y_mean)
y_hat_at_x_mean = a + b * x_mean
print(f"y_mean : {y_mean:.4f}")
print(f"y_hat at x_mean : {y_hat_at_x_mean:.4f}")y_mean : 294.0552
y_hat at x_mean : 294.0552
5.2. Drawing the Best-Fit Line¶
Let’s now draw the regression line on top of our scatter plot to see how well it fits the data.
x_range = np.linspace(x.min(), x.max(), 200)
y_hat = a + b * x_range
fig, ax = plt.subplots()
ax.scatter(x, y, alpha=0.35, color="steelblue",
edgecolors="white", s=60, label="Players")
ax.plot(x_range, y_hat, color="crimson", linewidth=2.5,
label=f"y_hat = {a:.2f} + {b:.3f} * x (r = {r:.3f})")
ax.set_xlabel("Games played", fontsize=12)
ax.set_ylabel("Salary Rank", fontsize=12)
ax.set_title("NBA Players: Regression Line (Games vs. Salary Rank)", fontsize=14)
ax.legend(fontsize=10)
plt.tight_layout()
plt.show()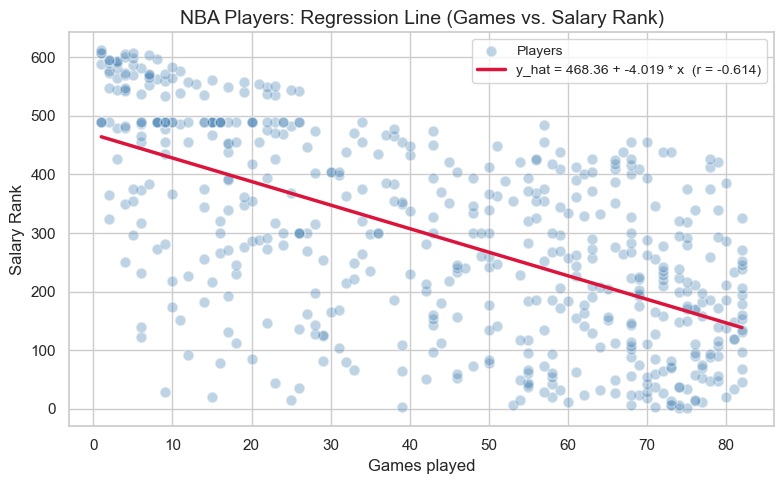
5.2.1 Interactive: Try Your Own Line¶
OpenStax emphasizes that the least-squares line is the line that makes the total squared error as small as possible.
Use the sliders below to choose your own slope and intercept. Compare your line to the best-fit line and watch the SSE (sum of squared errors).
Smaller SSE = better fit
The best-fit line should usually have one of the smallest SSE values
show_interactive_line_tuner(
x=x, y=y, a=a, b=b, x_range=x_range, y_hat=y_hat,
x_label="Games played", y_label="Salary Rank", money_yaxis=False,
)Question 5.1 (Code Practice — instructor solution). The next code cell shows the completed slope interpretation.
# Instructor solution: interpret slope b in context
rank_change_per_game = b
games_increase = 1
predicted_change = rank_change_per_game * games_increase
print(f"For each +{games_increase} game played, predicted salary rank changes by {predicted_change:.4f}.")
For each +1 game played, predicted salary rank changes by -4.0190.
5.3. Making Predictions¶
One of the most useful things about the regression line is that we can plug in any number of Games played to get a predicted Salary Rank. Use the slider below to explore predictions for different values of games played!
⚠️ Important: Predictions are only reliable within the range of the data. Predicting far outside this range — called extrapolation — can lead to unreliable results.
show_prediction_slider(
x=x, y=y, a=a, b=b, x_range=x_range, y_hat=y_hat,
x_label="Games played", y_label="Salary Rank", money_yaxis=False,
slider_description="Games played:",
)Question 5.2. Use the slider to find the predicted Salary Rank for a player who played 75 games. Then verify your answer by completing the code cell below using the regression equation a + b * x. Do both answers match?
# Instructor solution: predict Salary Rank for 75 games played using a + b * x
games_input = 75
predicted_rank = a + b * games_input
print(f"Predicted salary rank for {games_input} games played: {predicted_rank:.2f}")
Predicted salary rank for 75 games played: 166.93
Your Answer Here (does your manual calculation match the slider?)
6. Exploring Other Relationships (Sandbox)¶
Sections 5 and 6 modeled Salary Rank from Games played. The NBA dataset has many other numeric columns — points, salary, rebounds, assists, and more. How do other pairs compare?
In this sandbox section, you’ll pick any two numeric columns and run your own regression analysis using the dropdowns below.
6.1. Choosing Variables¶
# First, let's remind ourselves of all available numeric columns
numeric_cols = nba_clean.select_dtypes(include="number").columns.tolist()
print("Available numeric columns:")
print(numeric_cols)Available numeric columns:
['Salary Rank', 'Salary', 'Player Rank', 'Age', 'Games', 'Rebounds', 'Assists', 'Steals', 'Blocks', 'Turnovers', 'Points']
# Choose your x and y variables using the dropdowns, then click Run Regression
show_sandbox_regression(nba_clean)Question 6.1. Which pair of variables did you choose to explore? Before running the regression, what did you expect — a positive relationship, a negative relationship, or no relationship? Explain your intuition.
Your Answer Here
6.2. Running Your Own Regression¶
Question 6.2. What did you actually find? Report the correlation coefficient r for your chosen pair. Is the relationship stronger or weaker than the Games vs Salary Rank relationship from Section 5? Does the result match what you expected in Question 6.1?
Your Answer Here
7. Conclusion¶
In this notebook, we explored the core ideas of Linear Regression and Correlation using real NBA player data:
A scatter plot is the essential first step for understanding the relationship between two numeric variables.
The correlation coefficient r (between -1 and +1) measures how strongly and in what direction two variables are linearly related.
The regression line is the best-fit line through the data, computed from r, the standard deviations, and the means of x and y.
We can use the regression line to predict values of y for a given x — but only reliably within the observed range of the data (no extrapolation!).
These tools form the foundation for more advanced modeling in data science and statistics. Nice work! 🎉
Want to explore further? Try looking at whether MIN (minutes played) predicts Points better than any salary-related variable, or compare how correlations differ across player positions.
📋 Post-Notebook Reflection Form¶
Thank you for completing the notebook! We’d love to hear your thoughts so we can continue improving and creating content that supports your learning.
Please take a few minutes to fill out this short reflection form:
👉 Click here to fill out the Reflection Form
🧠 Why it matters:¶
Your feedback helps us understand:
How clear and helpful the notebook was
What you learned from the experience
What topics you’d like to see in the future
This form is anonymous and should take less than 5 minutes to complete.
We appreciate your time and honest input! 💬
Woohoo! You have completed this notebook! 🚀